Serving Layer
REST API + Interactive Dashboard
The batch pipeline writes Parquet outputs once (or on schedule). The FastAPI server is the low-latency serving layer on top: reads outputs, caches DataFrames in memory with a 1-hour TTL, and answers queries in milliseconds.
| Method | Path | Purpose | Latency |
|---|
| GET |
/health |
Liveness check: returns available stores and cache status |
<1 ms |
| GET |
/stores |
Lists all stores with completed pipeline outputs |
<1 ms |
| GET |
/stores/{store}/items |
Lists item IDs, filterable by category or department |
<5 ms |
| GET |
/forecast/{store}/{item_id} |
28-day point + quantile forecast (pre-computed from Parquet) |
<5 ms |
| POST |
/inventory |
Live inventory params: any lead time or service level |
<1 ms |
| GET |
/metrics/{store} |
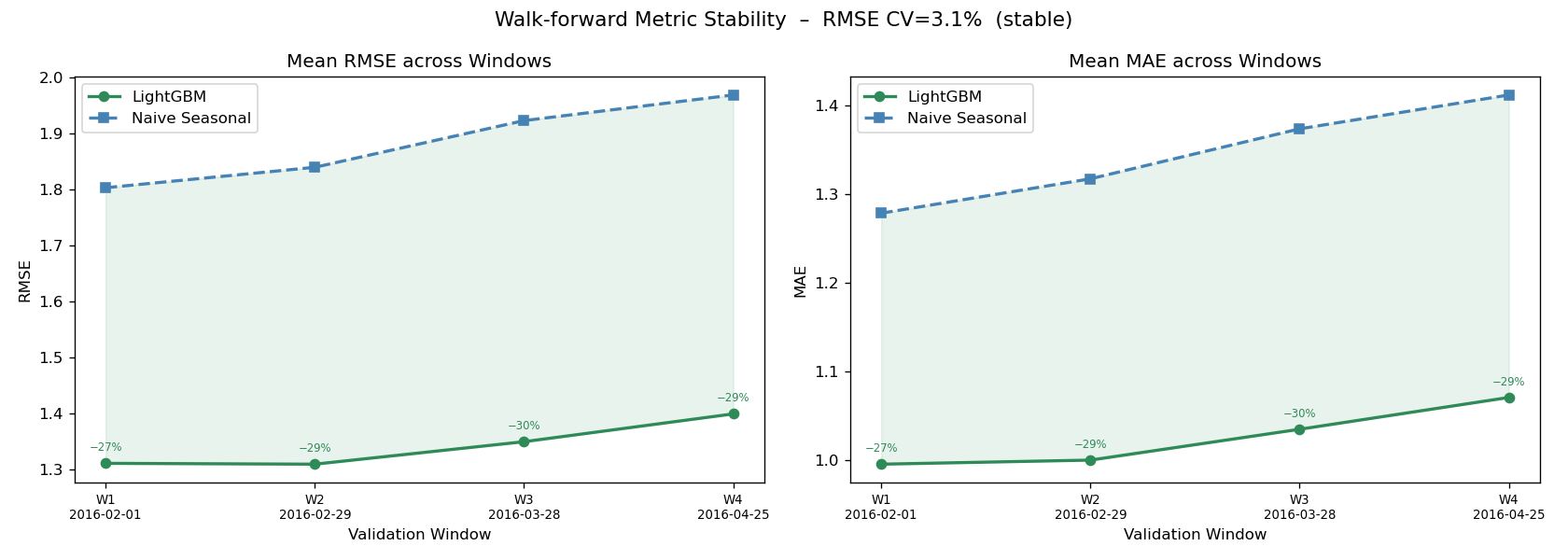
Store-level WRMSSE and walk-forward CV |
<2 ms |
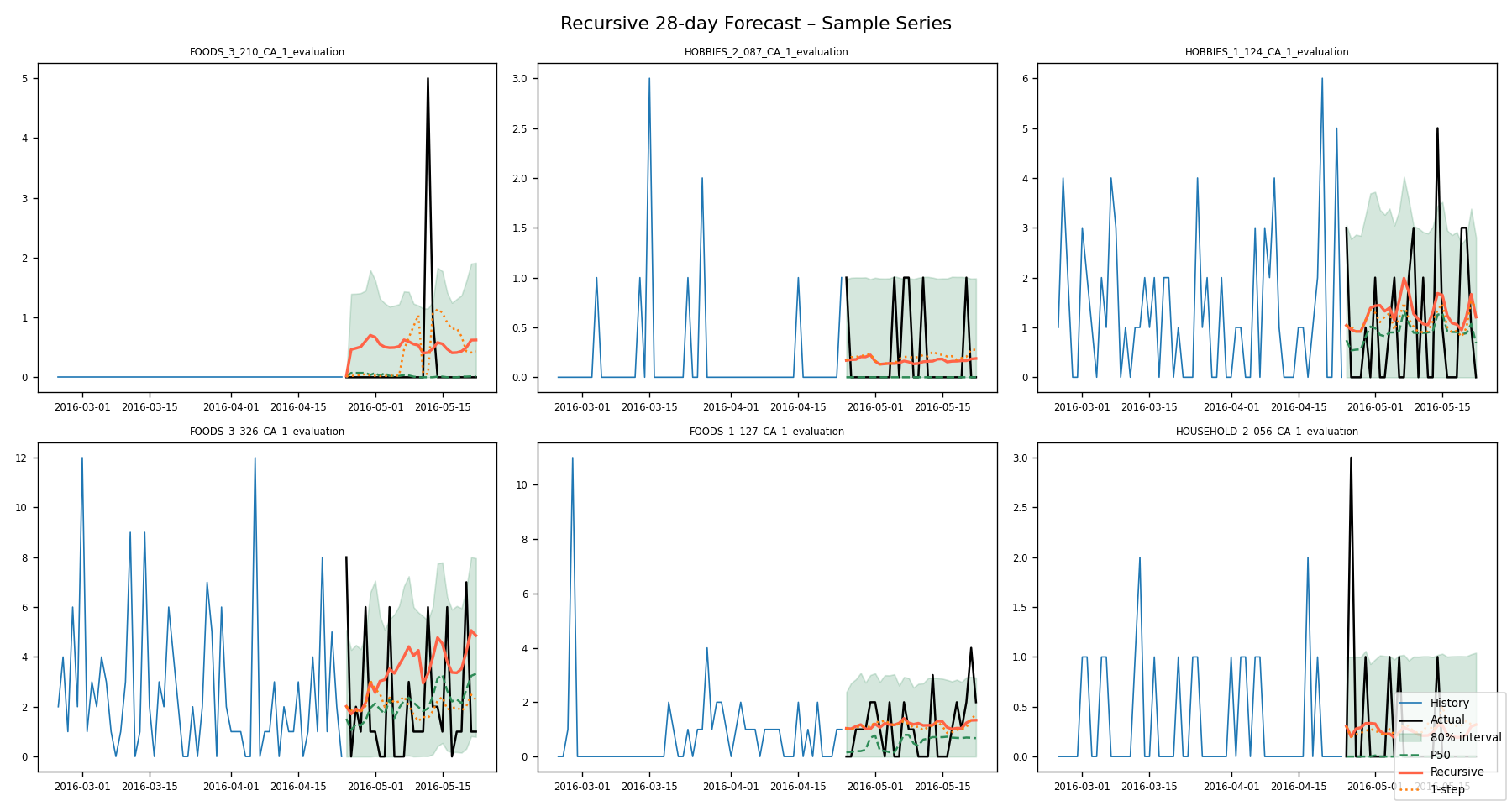
Design note: /forecast reads from Parquet, not from the live model. This means sub-millisecond response times at the cost of freshness (refresh by re-running Phase 5). /inventory computes on-the-fly, letting users query any lead time or service level without re-running Phase 6.
Example: Forecast Response
GET /forecast/CA_1/FOODS_1_001_CA_1_evaluation
{
"store": "CA_1",
"item_id": "FOODS_1_001_CA_1_evaluation",
"n_days": 28,
"forecasts": [
{
"date": "2016-04-25",
"pred_point": 0.7978,
"pred_q10": 0.0,
"pred_q50": 0.9599,
"pred_q90": 2.5654,
"actual_sales": 2.0
},
... 27 more days
]
}
Example: Inventory Response
POST /inventory
{ "store": "CA_1", "item_id": "FOODS_1_001_CA_1_evaluation",
"lead_time": 7, "service_level": 0.95 }
{
"mean_daily_demand": 0.861,
"demand_std_daily": 0.902,
"lead_time_demand": 6.02,
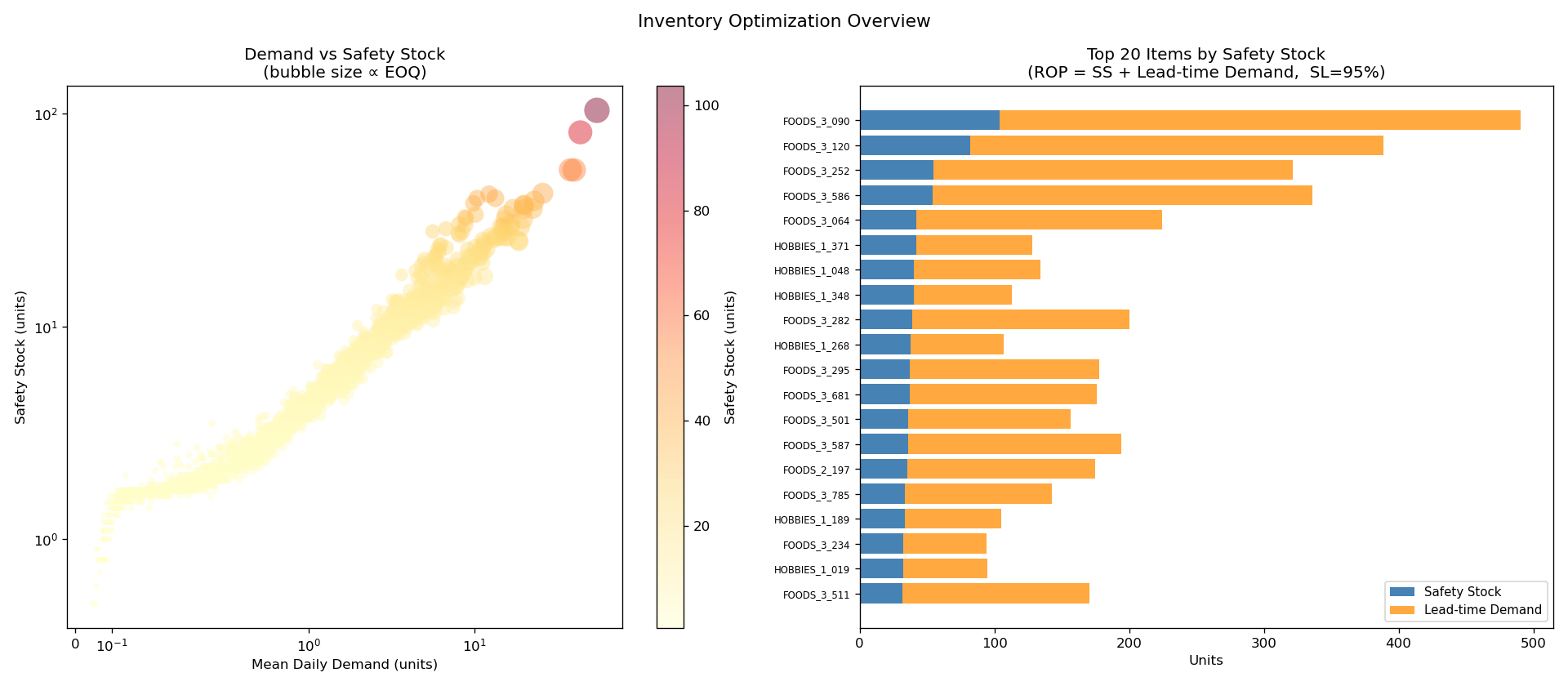
"safety_stock": 3.9, ← hold this much buffer
"reorder_point": 9.9, ← order when stock hits this
"eoq": 396.3, ← order this many units
"days_of_supply_ss": 4.6
}
Tech Stack
Data Processing
pandas, numpy, pyarrow, fastparquet
ML / Forecasting
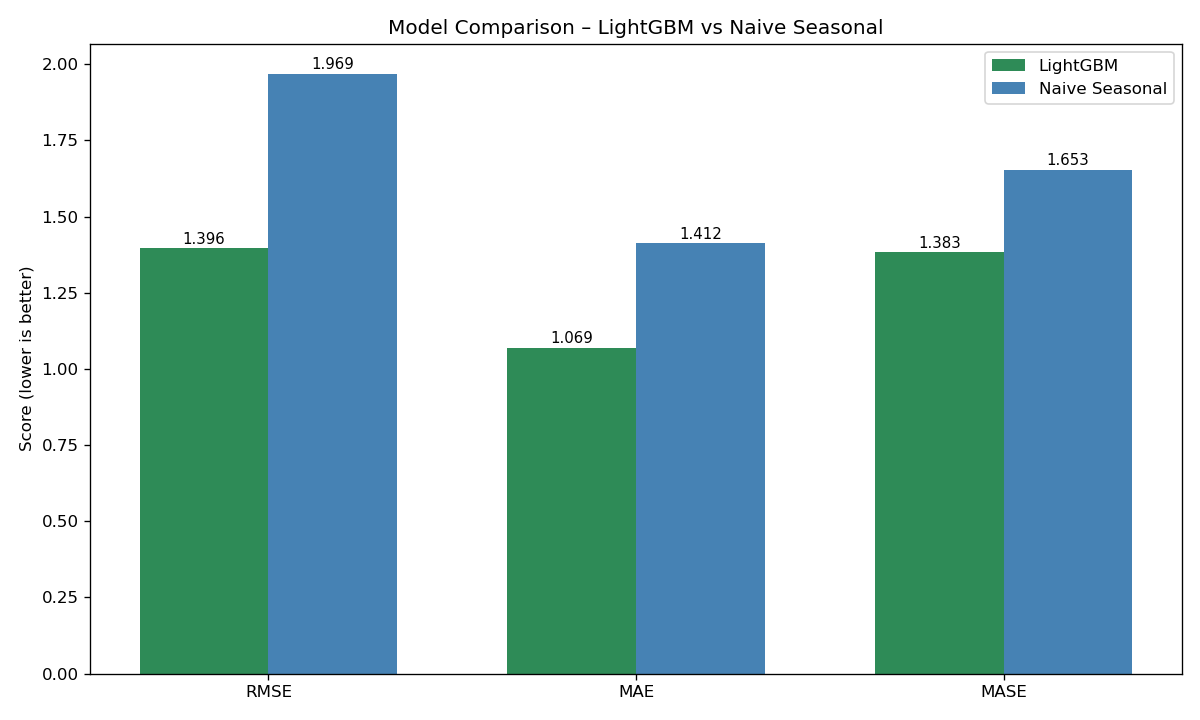
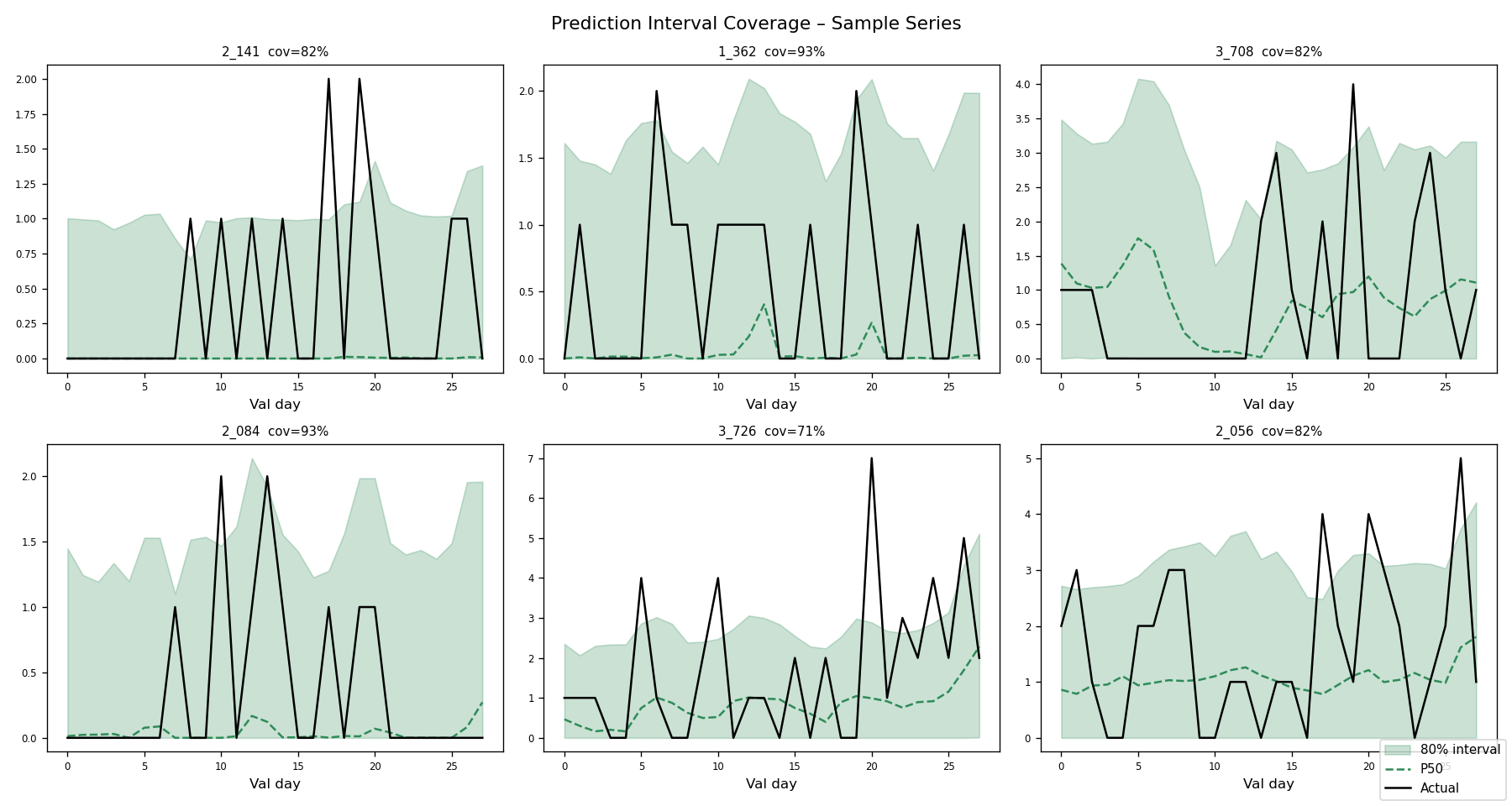
LightGBM, statsmodels (ARIMA), Prophet, scikit-learn
Optimization
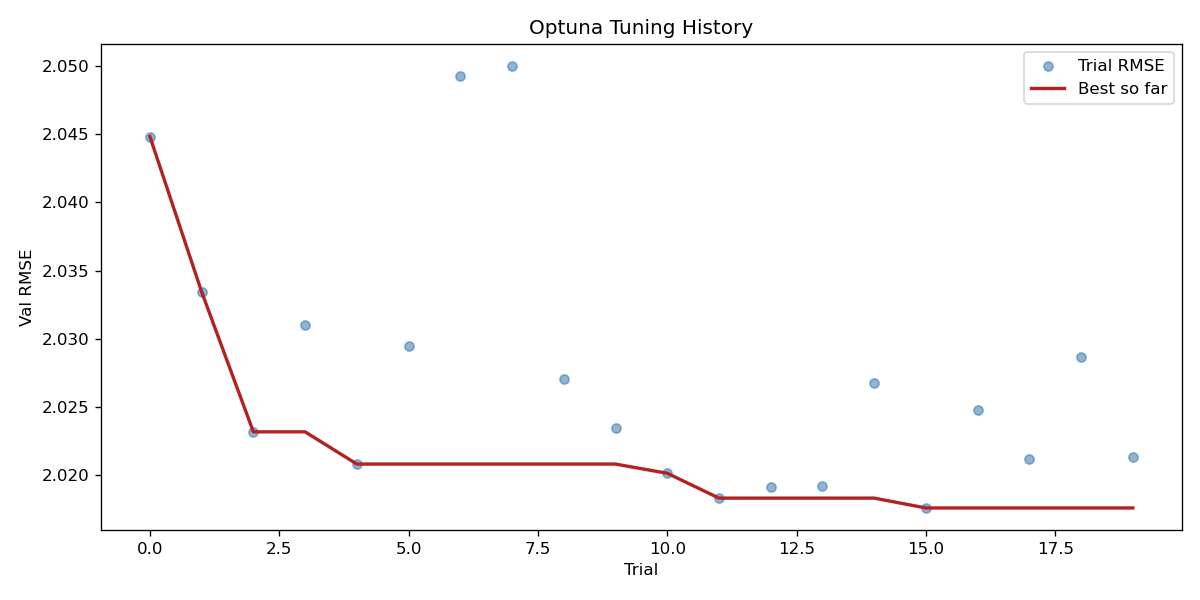
Optuna (TPE sampler), 20-trial Bayesian HPO
Visualization
matplotlib, seaborn, plotly
API / Serving
FastAPI, uvicorn, Pydantic v2, TTL in-process cache
Dashboard
Streamlit (5-tab interactive app with live parameter sliders)